Here are a selection of research projects that I have worked on over the years.
Chatbots or conversational agents (CAs) are increasingly used to improve access to digital psychotherapy. Many current systems rely on rigid, rule-based designs, heavily dependent on expert-crafted dialogue scripts for guiding therapeutic conversations. Although recent advances in large language models (LLMs) offer the potential for more flexible interactions, their lack of controllability and transparency poses significant challenges in sensitive areas like psychotherapy. In this work, we explored how aligning LLMs with expert-crafted scripts can enhance psychotherapeutic chatbot performance. Our comparative study showed that LLMs aligned with expert-crafted scripts through prompting and fine-tuning significantly outperformed both pure LLMs and rule-based chatbots, achieving a more effective balance between dialogue flexibility and adherence to therapeutic principles. Building on findings, we proposed ``Script-Strategy Aligned Generation (SSAG)’’, a flexible alignment approach that reduces reliance on fully scripted content while enhancing LLMs’ therapeutic adherence and controllability. In a 10-day field study, SSAG demonstrated performance comparable to full script alignment and outperformed rule-based chatbots, empirically supporting SSAG as an efficient approach for aligning LLMs with domain expertise. Our work advances LLM applications in psychotherapy by providing a controllable, adaptable, and scalable solution for digital interventions, reducing reliance on expert effort. It also provides a collaborative framework for domain experts and developers to efficiently build expertise-aligned chatbots, broadening access to psychotherapy and behavioral interventions.
As AI-generated health information proliferates online and becomes increasingly indistinguishable from human-sourced information, it becomes critical to understand how we trust and label such content, especially should such information be inaccurate. We conducted a mixed-methods survey (N=142) and within-subjects lab study (N=40) to investigate how health information source (Human, LLM), type (General, Symptom, Treatment), and disclosed label (Human, AI) influence perceived trust, behavior, and physiological indicators. We found that AI content is trusted more than human content, regardless of labeling, whereas human labels are trusted more than AI labels. Trust remained consistent across information types. Eye-tracking and physiological responses varied significantly by source and label, reaching 73% accuracy and 0.35 R$^2$ in predicting perceived trust, and 65% in classifying the source. We show that adding transparency labels to online health information modulates trust, where behavioral and physiological features may help verify trust perceptions and indicate if additional transparency is needed.
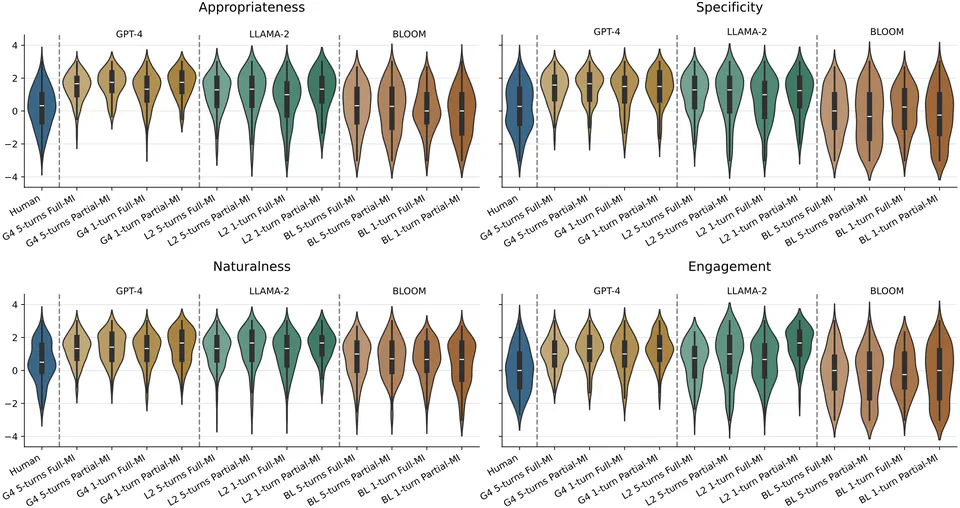
Motivational Interviewing (MI) is a counseling technique that promotes behavioral change through reflective responses to mirror or refine client statements. While advanced Large Language Models (LLMs) can generate engaging dialogues, challenges remain for applying them in a sensitive context such as MI. This work assesses the potential of LLMs to generate MI reflections via three LLMs: GPT-4, Llama-2, and BLOOM, and explores the effect of dialogue context size and integration of MI strategies for reflection generation by LLMs. We conduct evaluations using both automatic metrics and human judges on four criteria: appropriateness, relevance, engagement, and naturalness, to assess whether these LLMs can accurately generate the nuanced therapeutic communication required in MI. While we demonstrate LLMs’ potential in generating MI reflections comparable to human therapists, content analysis shows that significant challenges remain. By identifying the strengths and limitations of LLMs in generating empathetic and contextually appropriate reflections in MI, this work contributes to the ongoing dialogue in enhancing LLM’s role in therapeutic counseling.
The deployment of Conversational User Interfaces (CUIs) with advanced Large Language Models (LLMs) has significantly transformed health information seeking and dissemination, facilitating immediate and interactive communication between users and digital health resources. However, while trust is crucial for adopting online health advice, how the dissemination interface influences people’s perceived trust in health information provided by LLMs remains unclear. To address this, we conducted a mixed-methods, within-subjects lab study (N=20) to investigate how different CUIs (i.e., a text-based, speech-based, and embodied interface) affect user-perceived trust levels when delivering health information from an identical LLM source. Our key findings showed that: (a) participants’ trust levels in health information delivered were significantly variant across different interfaces; (b) there is a significant correlation between trust in health-related information and trust in the delivered user interface as well as the usability level of the user interface; (c) the type of health questions did not affect participants’ perceived trust; and (d) participants’ prior experience with various interfaces, processing approaches for information with different modalities, and presentation styles were key determinants of trust in health-related information. Our study taps into differences in trust perceptions of health information from LLMs and its dissemination. We highlight the potential of various LLM-powered CUIs in health-related information-seeking contexts. We contribute key factors and considerations for ensuring effective and reliable personal health information seeking in the age of LLM-powered CUIs and multi-modal information dissemination.
Behavioral coding (BC) in motivational interviewing (MI) holds great potential for enhancing the efficacy of MI counseling. However, manual coding is labor-intensive, and automation efforts are hindered by the lack of data due to the privacy of psychotherapy. To address these challenges, we introduce BiMISC, a bilingual dataset of MI conversations in English and Dutch, sourced from real counseling sessions. Expert annotations in BiMISC adhere strictly to the motivational interviewing skills code (MISC) scheme, offering a pivotal resource for MI research. Additionally, we present a novel approach to elicit the MISC expertise from Large language models (LLMs) for MI coding. Through the in-depth analysis of BiMISC and the evaluation of our proposed approach, we demonstrate that the LLM-based approach yields results closely aligned with expert annotations and maintains consistent performance across different languages. Our contributions not only furnish the MI community with a valuable bilingual dataset but also spotlight the potential of LLMs in MI coding, laying the foundation for future MI research.